Large language models (LLMs) and large multimodal models (LMMs) have significantly impacted the AI community, industry, and various economic sectors. In journalism, integrating AI poses unique challenges and opportunities, particularly in enhancing the quality and efficiency of news reporting. This study explores how LLMs and LMMs can assist journalistic practice by generating contextualised captions for images accompanying news articles.

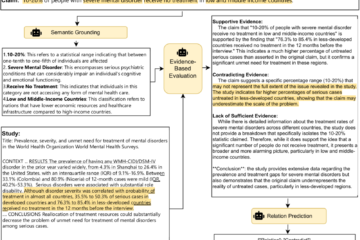
Figure 1: An example from the GoodNews dataset and the extracted context we used
We conducted experiments using the GoodNews [1] dataset to evaluate the ability of LMMs to incorporate one of two types of context: entire news articles, or extracted named entities. In addition, we compared their performance to a two-stage pipeline composed of a captioning model with post-hoc contextualisation with LLMs.
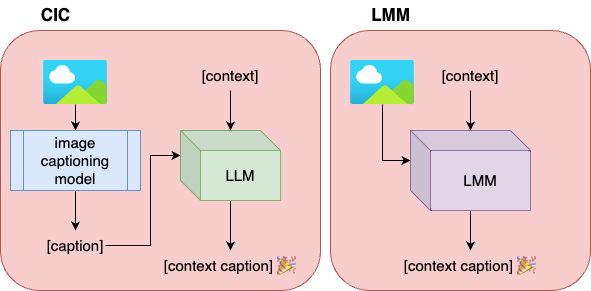
Figure 2: Our proposed pipeline, compared to an LMM
By assessing a diversity of models and evaluating with automated metrics, we concluded the following:
- The bottleneck caused by using a two-stage architecture with a textual description of the image rather than the image itself is insignificant. Close-source models such as the GPT family might have an advantage in this configuration.
- However, smaller, open-source LMMs perform similarly well as proprietary ones.
- In terms of context, focused information, such as named entities, is more beneficial to the models than the whole article itself. This finding indicated a possible future direction for our work: implementing an interactive system that facilitates journalists’ writing captions for their articles.
Note: The paper “Enhancing Journalism with AI: A Study of Contextualized Image Captioning for News Articles using LLMs and LMMs” [2], in which these approaches are presented, was accepted at the workshop TIDMwFM@IJCAI’24.
Citations:
[1] Biten, A. F., Gómez, L., Rusiñol, M., & Karatzas, D. (2019). Good News, Everyone! Context Driven Entity-Aware Captioning for News Images. IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, 12466–12475. doi:10.1109/CVPR.2019.01275
[2] Anagnostopoulou, A., Gouvêa, T. S., & Sonntag, D. (2024). Enhancing Journalism with AI: A Study of Contextualized Image Captioning for News Articles using LLMs and LMMs. Trustworthy Interactive Decision Making with Foundation Models workshop, 33rd International Joint Conference on Artificial Intelligence.
Authors:
Aliki Anagnostopoulou, Thiago Gouvêa