Image captioning has seen immense progress in the last few years. However, general-purpose systems often fail to provide personalised, context-aware captions tailored to individual users or domains. In this work, we investigate the task of personalised and contextualised image captioning by leveraging foundational models, including large language models (LLMs) and large multimodal models (LMMs). As pre-trained vision-language systems fail to capture details about the user’s intent, occasion, and other information related to the image input, we envision a system that addresses these limitations. This approach has two key components for which we need to find suitable practical implementations: multimodal RAG (mRAG) and automatic prompt engineering.

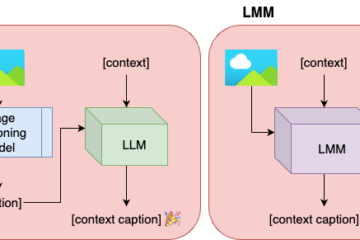
As our baseline, we follow an approach [1] leveraging a conventional image captioning component for the extraction of visual information from the image in the form of a base caption, and an LLM, which can generate a contextualised caption using the base caption and the context information provided. We experiment with various image captioning and LLM combinations. To alleviate the information bottleneck in our two-stage pipeline, we employ dense captioning, generating captions for detected objects. We additionally plan to fine-tune open-source LLMs for the tasks of context extraction and contextualised caption generation.
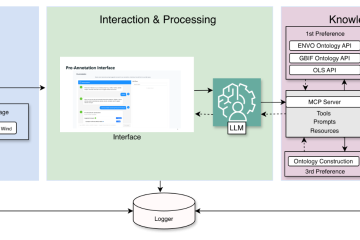
A mRAG system searches for relevant data. The goal is to extract additional context or information that enhances the caption by making it more personalized or contextually accurate. In the case of user-specific data, past captions, user preferences, and feedback to the caption generation process are considered. We leverage multi-agentic approaches to employ task-specific REasoning and ACTing (REACT) [2] agents to enhance information retrieval. In the case of domain-specific context, relevant knowledge from sources such as journalism archives or Wikipedia articles can be retrieved.
We are additionally implementing a version of automatic prompt engineering based on APE [3] to enhance the performance of the LLMs. This includes:
- instruction induction given initial input-desired output pairs,
- instruction summarization and paraphrasing for the diversification of prompts,
- instruction refinement, and
- storing of high-scoring candidates for future use by the specific user.
We compare the performance improvement of our automatic prompt engineering method to that of fine-tuned models.
Citations:
[1] Anagnostopoulou, A., Gouvêa, T. S., & Sonntag, D. (2024). Enhancing Journalism with AI: A Study of Contextualized Image Captioning for News Articles using LLMs and LMMs. Trustworthy Interactive Decision Making with Foundation Models workshop, 33rd International Joint Conference on Artificial Intelligence.
[2] Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K. R., & Cao, Y. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023.
[3] Zhou, Y., Muresanu, A. I., Han, Z., Paster, K., Pitis, S., Chan, H., & Ba, J. (2023). Large Language Models are Human-Level Prompt Engineers. The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023.
Authors:
Aliki Anagnostopoulou, Hasan Md Tusfiqur Alam (Hasan_Md_Tusfiqur.Alam@dfki.de)