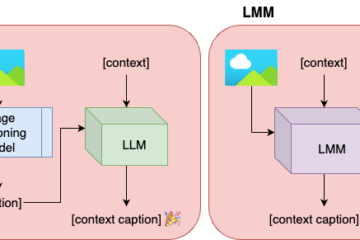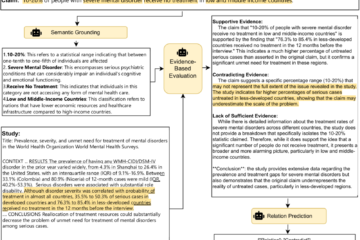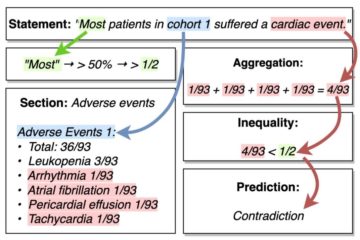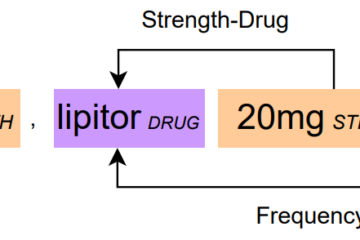
Computational Sustainability Machine Learning Natural Language Processing
Grounded Label Space Engineering for Knowledge-Centric Annotation Workflows
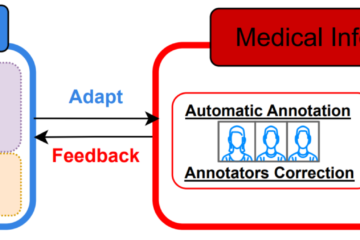
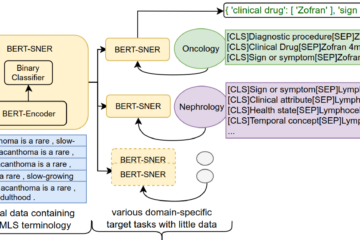
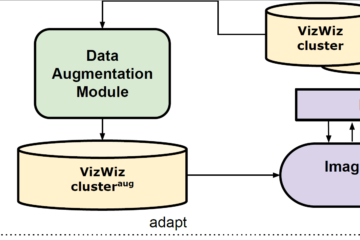
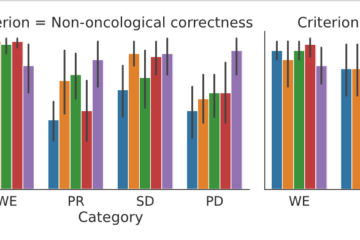
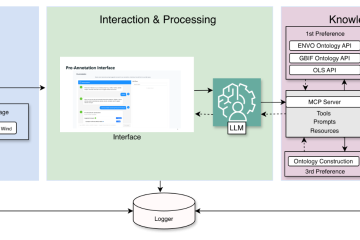
Building reliable AI models depends not only on how much data is annotated, but on the quality and meaning of the labels used during annotation. In many workflows, labels are flat, task-specific class names. They are easy to apply, but lack explicit semantic structure, provenance, and links to shared domain Read more