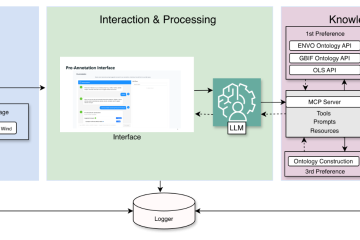
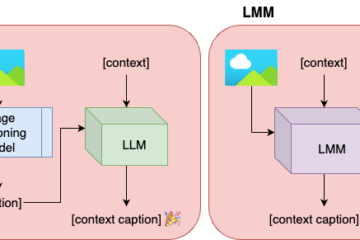
We present an interactive image captioning pipeline. Image captioning models take an image as input, for which they generate one or more captions, or descriptions in natural language. State-of-the-art image captioning systems are trained in an offline mode, namely with a big amount of data at once. With our approach, we aim for a model that learns incrementally, which can also be personalized and hence more user-friendly.
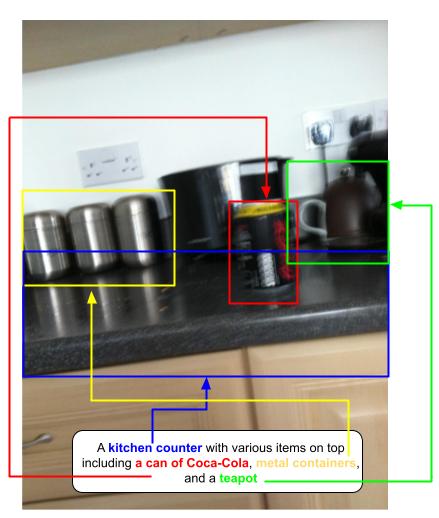
Pre-trained image captioning models might not perform as well with everyday images – either the quality of the image might pose an issue, or the need for a more personalized and contextualized description might be present. (Source: https://vizwiz.org/)
Using an image captioning model trained on a generic dataset as our basis, we re-train incrementally, with small data clusters serving as user feedback. In order to help the model learn better, we generate more training instances out of these clusters, applying data augmentation on the training instances. We apply data augmentation on image only, text only, and both modalities. We also work on a joint data augmentation method, which takes into consideration the modifications in the input image and modifies the golden caption accordingly.
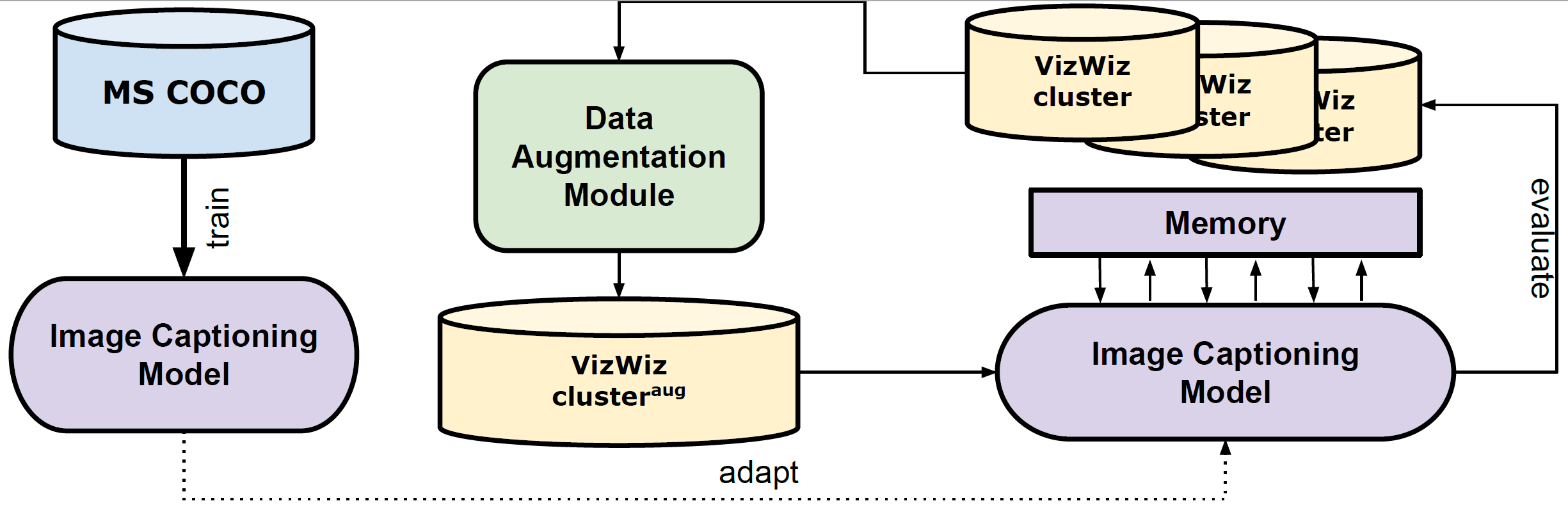
Since deep neural networks tend to ‘forget’ previous knowledge when re-trained repeatedly, we implement a continual learning method, namely Episodic Memory, which prevents this catastrophic forgetting.
For evaluation, we simulate user feedback using a domain-specific dataset (VizWiz). It consists of images taken by visually impaired individuals. We split this dataset into thematically coherent five clusters of unequal length. We find this dataset to be ideal for our use case, given its small size and relatively poor image quality.
We find out that our data augmentation methods do not contribute to better results, Episodic Memory does help retain knowledge from clusters previously seen by the model. In future, we plan to explore more data augmentation methods which would be more effective for our data. We also want to refine our Episodic Memory module, experimenting with local adaptation during inference time and active learning for the selection of informative samples for memory writing.
The paper “Towards Adaptable and Interactive Image Captioning with Data Augmentation and Episodic Memory“, in which these approaches are presented, was accepted at the workshop SustaiNLP 2023.