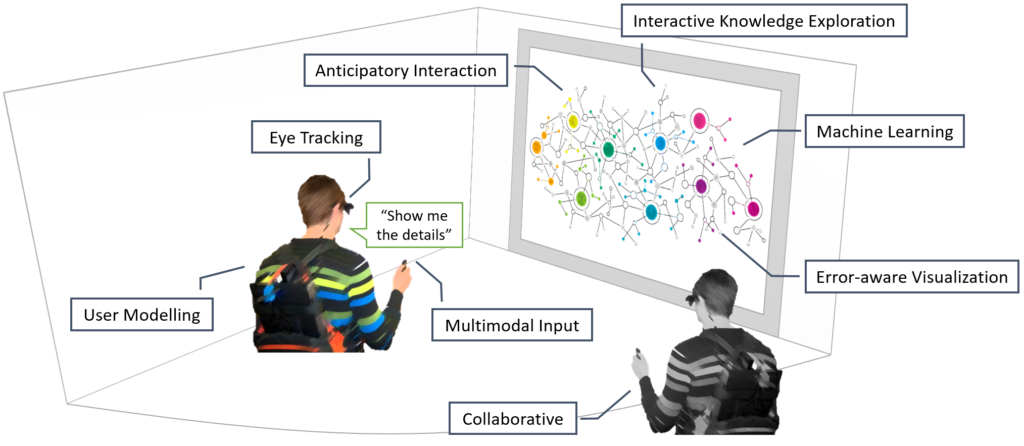
In this project, we consider scenarios which include one or more expert users that interact with a multimodal-multisensor interface. In particular, we focus on applications of eye tracking and speech-based input for semantic search applications, e.g., interactive knowledge exploration. We aim at developing interaction techniques for individual modalities, combinations thereof and at modelling their interplay with the application context. Our goal is to improve the robustness of the human-computer interaction, also by facilitating incremental model improvements through multimodal signal analysis.