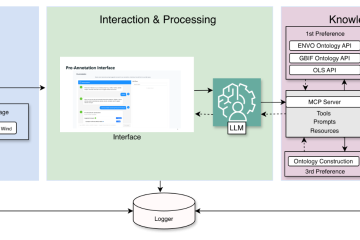
In the Autoprompt project funded by a grant from Accenture, one of the world’s leading consulting, technology and outsourcing companies, we focus on developing automated biomedical claim verification systems designed to assist clinicians and researchers in addressing the risks posed by misinformation in the healthcare domain. By providing accurate, evidence-based assessments, these systems enhance decision-making and support the integrity of healthcare information. The primary functionality of the system is to assist users in validating claims by leveraging the strengths of LLM-based verification while ensuring a transparent and reliable decision-making process [1]. The system builds on the Chain of Evidential Natural Language Inference (CoENLI) framework (see Fig. 1), which enables LLMs to generate evidence-based rationales before arriving at a final relation classification. To further enhance the interpretability of the system, we integrate Shapley Additive exPlanations (SHAP) saliency maps [2], which highlight the word-level contributions within the generated rationales corresponding to specific logical categories: support, contradict or not enough information (see Fig. 2). After reviewing the generated rationales and saliency maps, if the users disagree with the initial classification result, they can adjust it, prompting the model to generate a concise justification for the updated classification (see Fig. 3).
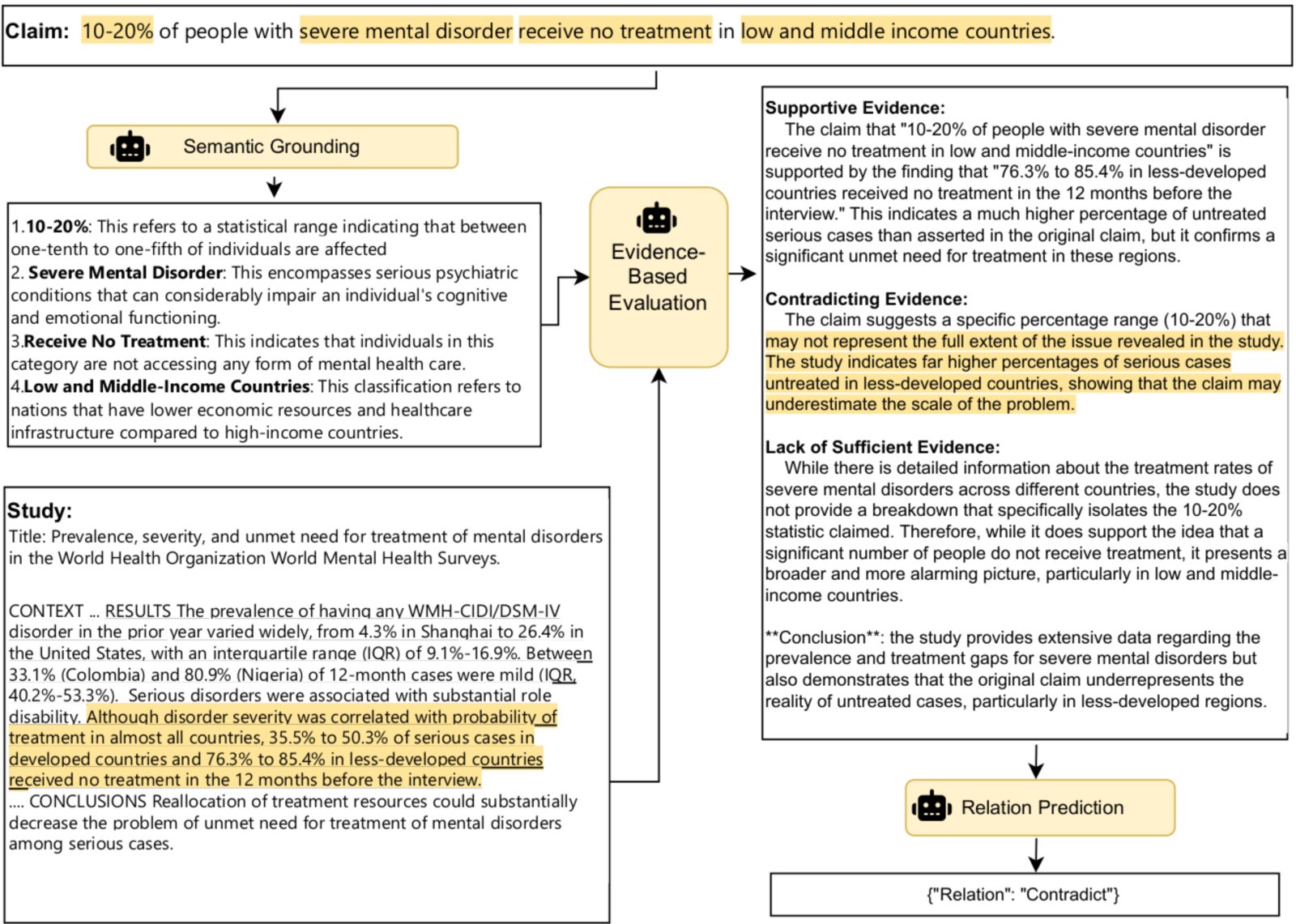
Figure. 1 When prompting the LLMs with CoENLI framework, the process begins with ”Semantic Grounding” and ”Evidence-based Evaluation” steps. These steps help interpret key terms and assess each piece of claim against identified relevant data points. The highlighted words and phrases in the claim, study, and generated evaluation are intended to offer plausible insights involved in the claim verification process.
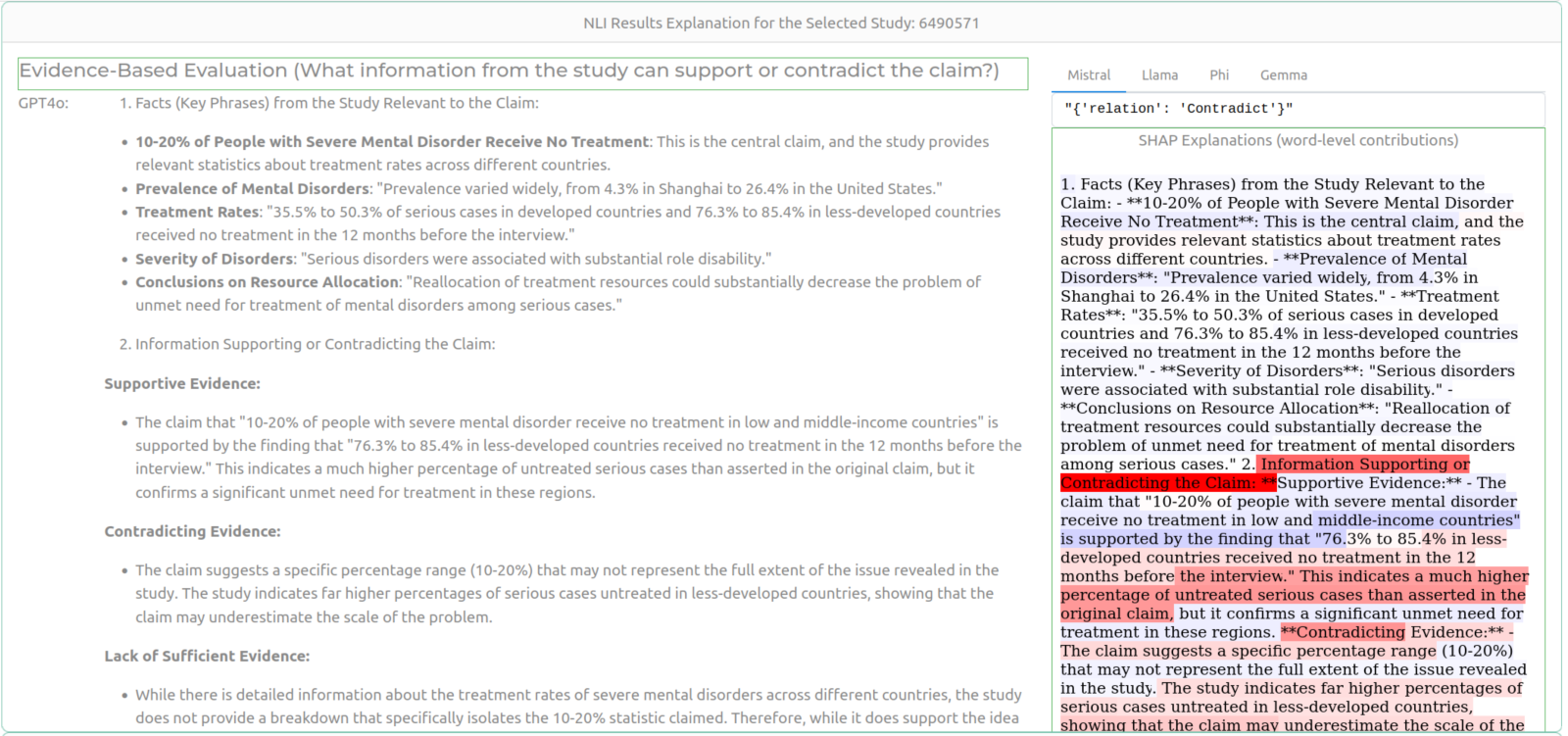
Figure. 2 The system provides users dual-layer interpretability for a deeper understanding of verification results by combining evidence analysis with SHAP-based rationale highlighting.

Figure 3. Users can adjust the classification results and prompt the model to generate a final justification for the final decision.
References
[1] Neema Kotonya and Francesca Toni. 2020. Explainable Automated Fact-Checking for Public Health Claims. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 7740–7754.
[2] Scott Lundberg. 2017. A unified approach to interpreting model predictions. arXiv preprint arXiv:1705.07874 (2017).
Contact
Siting Liang (Siting.Liang@dfki.de)