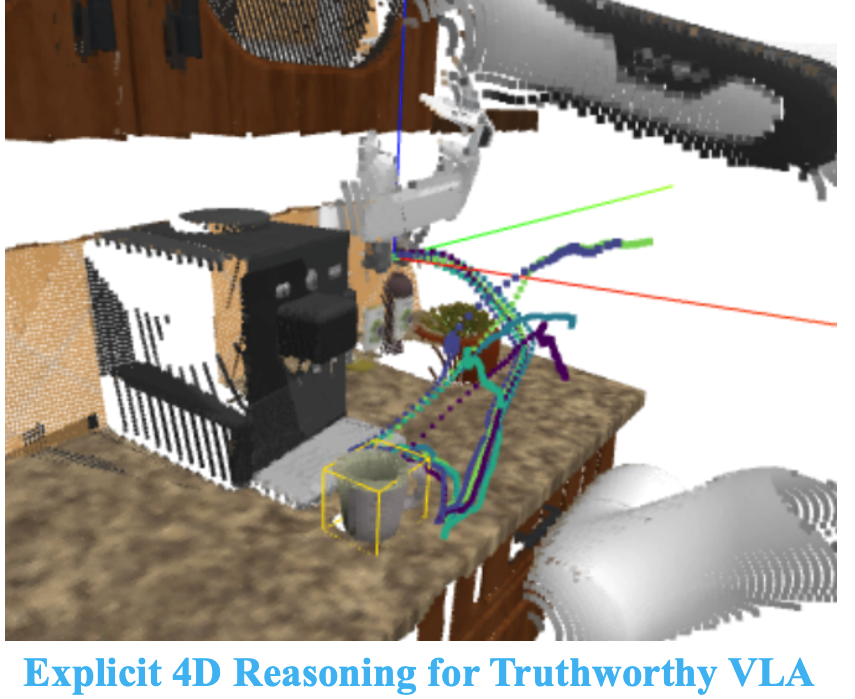
Visual-Language-Action (VLA) models are typically trained through imitation learning, which teaches policies to reproduce demonstrated actions but provides limited supervision about the conditions that define task success.
We propose a framework that automatically extracts executable 3D task verifiers from demonstrations and uses them to improve policy learning beyond imitation.
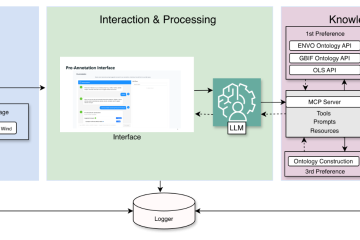
Given task instructions and demonstration trajectories, a vision-language model infers stage-wise success constraints grounded in reconstructed 3D scene geometry. Starting from a pretrained VLA, we generate counterfactual action sequences and imagine their consequences in a reconstructed 3D world without executing them on a robot. The inferred verifiers evaluate these imagined interactions, producing additional successful and failed trajectories for training.
Unlike reward-learning approaches, our method represents task knowledge as structured verification predicates rather than scalar rewards. We hypothesize that learning from verifier-guided imagined successes and failures enables improved task understanding, robustness, and generalization while requiring no additional robot interaction.
References
Tran, T., Nguyen, H. M. D., Tran, H.-C., Barz, M., Doan, K. D., Wattenhofer, R., Vien, N. A., Niepert, M., Sonntag, D., & Swoboda, P. (2025). How many tokens do 3D point cloud transformer architectures really need? In: The Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS). Neural Information Processing Systems (NeurIPS-2025), December 2-12, USA, Advances in Neural Information Processing Systems, 12/2025.
Contact
Tuan Tran (Tuan.Tran@dfki.de)