Computational Sustainability
Human-Centred Active Learning through Visual Analytics
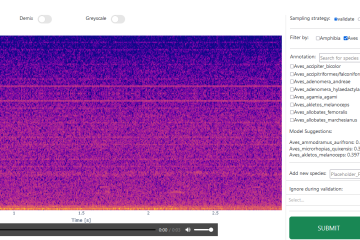
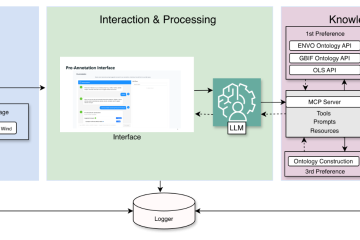
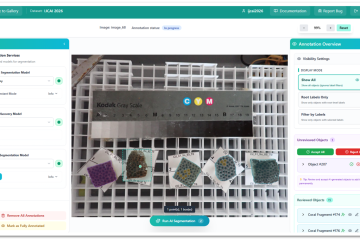
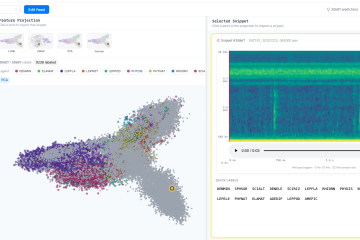
Machine learning models are powerful, yet they often sideline the domain experts who understand the data best. In conventional active learning pipelines, the model drives the process while the user simply responds, leaving domain knowledge underutilised and treating the annotator as a passive responder rather than an active contributor. This Read more