Natural Language Processing
A case study for contextualised image captioning uning foundation models: journalism enhancement with AI
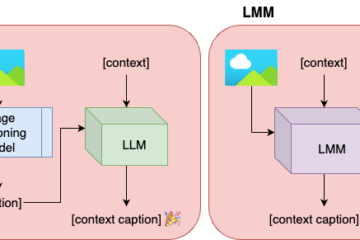
Large language models (LLMs) and large multimodal models (LMMs) have significantly impacted the AI community, industry, and various economic sectors. In journalism, integrating AI poses unique challenges and opportunities, particularly in enhancing the quality and efficiency of news reporting. This study explores how LLMs and LMMs can assist journalistic practice Read more
