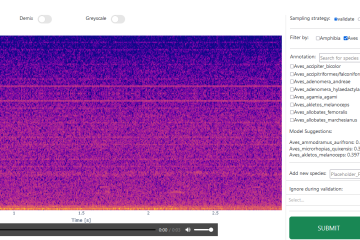
Machine learning models are powerful, yet they often sideline the domain experts who understand the data best. In conventional active learning pipelines, the model drives the process while the user simply responds, leaving domain knowledge underutilised and treating the annotator as a passive responder rather than an active contributor. This work investigates how to restore that balance. We ask how a model’s evolving internal representation of data can be mapped to visualisations that are both structurally faithful and intuitively interpretable, giving annotators the context and control they need to make informed labelling decisions. The tension we address is fundamental. Purely model-driven annotation is efficient but limited in scope; the model can only request labels for what it already knows to be uncertain, blind to the domain knowledge the expert brings. Purely user-driven annotation leverages that expertise but is slow and difficult to scale.
We build on the visual interactive labelling framework [1], which maps model guidance to visual channels to direct annotator attention toward informative samples, and on work unifying visual interactive labelling with active learning [2]. We extend these foundations in several ways. First, we move beyond static visualisations to investigate how annotators interact with an evolving model representation space. Our user study demonstrates that user actions directly influence this space, supporting sensemaking and enabling more strategic labelling decisions [3]. Second, we extend this investigation into immersive environments, studying the cross-modal translation of visual interactive labelling to VR and developing a prototype that exploits the spatial and embodied affordances of immersive technology to further support the annotation process [4].
To ground this work in a real-world context, we apply it to bioacoustics, a domain where ecologists annotate passive acoustic monitoring datasets to identify events of interest, iteratively training models and expanding labelled datasets over time. To our knowledge, this is the first implementation of a mixed-initiative labelling environment in this domain, and the first to examine how such environments can support the full active learning annotation workflow with domain expert users. Our framework is actively used by annotators around the world and continues to evolve through an ongoing participatory design process.
We further plan to study how domain experts adapt their behaviour as they progressively move from a purely model-driven annotation setting toward full visual interactive labelling, examining how their strategies evolve at each stage as they learn to work alongside the model and navigate the information cues available in a mixed-initiative environment.
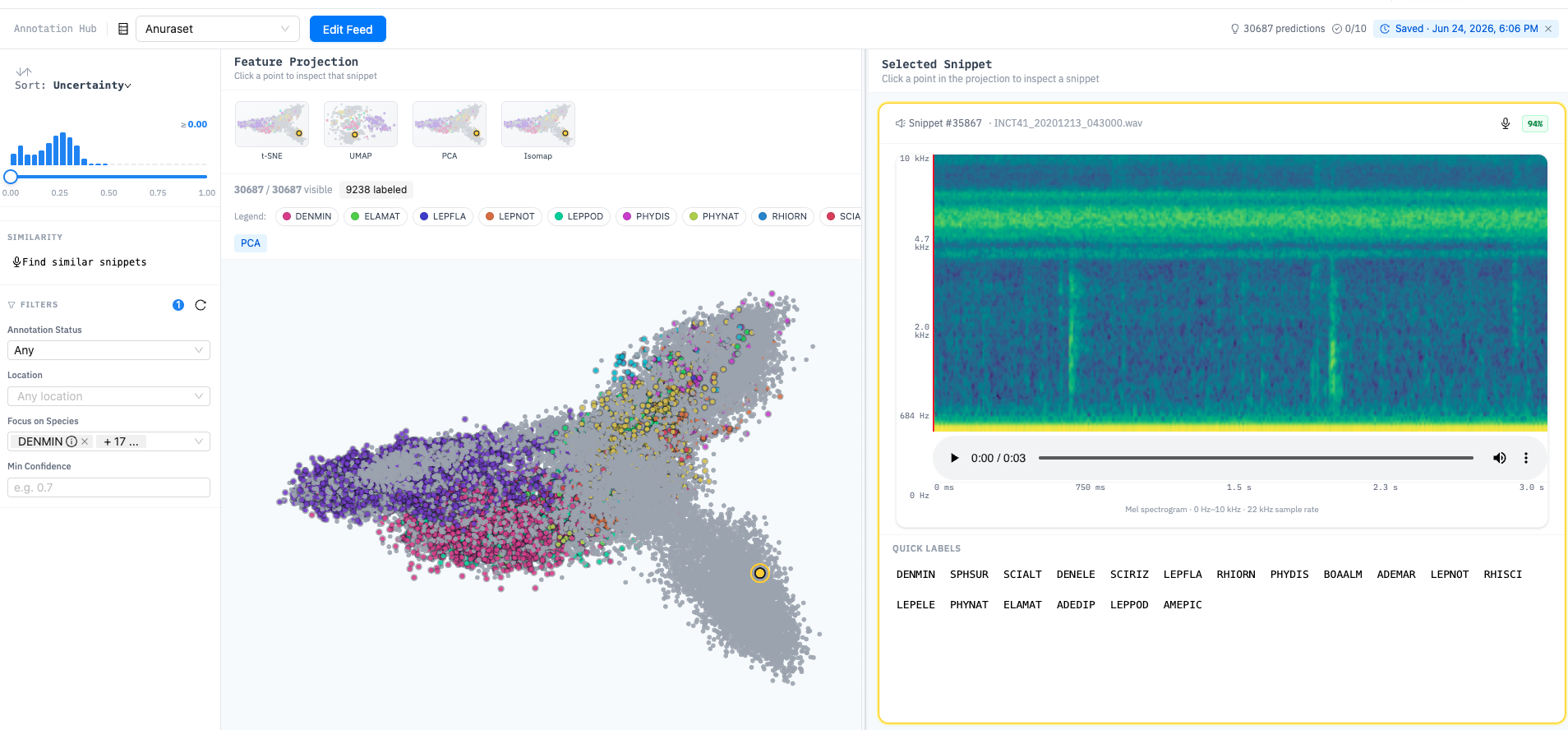
Screenshot of the bioacoustic annotation tool showing a feature projection of audio snippets coloured by species class, with a selected snippet’s mel spectrogram and quick label panel for annotation
References
[1] Bernard, J., Hutter, M., Zeppelzauer, M., Fellner, D., & Sedlmair, M. (2017). Comparing visual-interactive labeling with active learning: An experimental study. IEEE transactions on visualization and computer graphics, 24(1), 298-308.
[2] Bernard, J., Zeppelzauer, M., Sedlmair, M., & Aigner, W. (2018). VIAL: a unified process for visual interactive labeling. The Visual Computer, 34(9), 1189-1207.
[3] Saghir, R., et al. 2026. Visualizing and Interacting with Model Representation Space for Human-Centric Active Learning. In Proceedings of the 35th International Joint Conference on Artificial Intelligence (IJCAI 2026).
[4] Saghir, R., Ahmad, S., Kopácsi, L., Gouvêa, T. S., & Sonntag, D. (2026, March). User-Centric Active Learning Through Immersive Visualization. In 2026 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW) (pp. 1413-1414). IEEE.
Contact
Rida Saghir (Rida.Saghir@dfki.de)