We present a virtual reality (VR) application that enables interactive image clustering and fine-tuning of a deep neural network by using natural hand gestures. Using a pre-trained AlexNet, we apply PCA and t-SNE dimensionality reduction techniques to project image data sets into the 3D VR space. Resulting spatial clusters of class instances are visualized with their respective centroid and label. The user can interactively move images in the 3D space, thereby triggering the fine-tuning of the network, based on the new positional information and label of the image. After the fine-tuning step is finished, the visualization is updated according to the new output of the network.

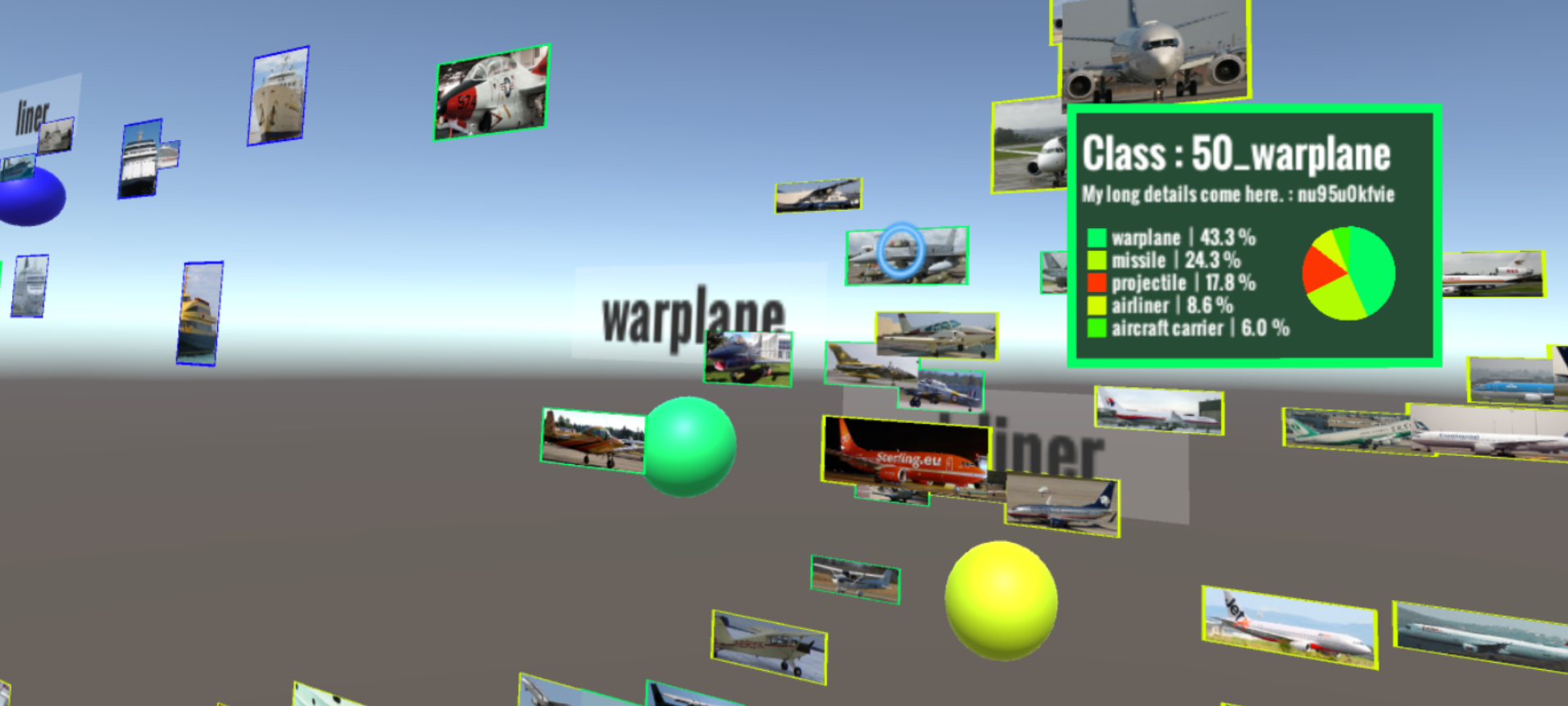
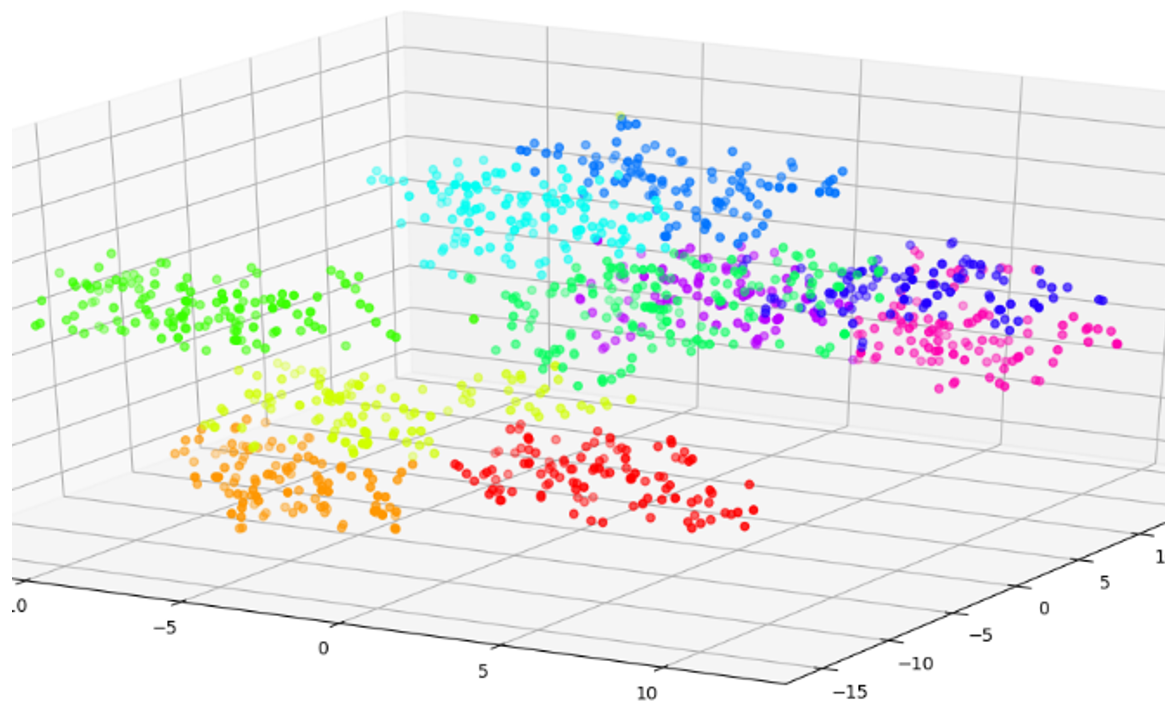
Images are visualized in VR according to their 3D vectors. Projected 3D vectors are normalized so that distances in all dimensions are perceived in an explorable VR space. Then we calculate cluster centers for each class in the projected space. We first apply PCA on the feature maps of the fc7 layer, reducing from 4096-d to 50-d. Next, we apply t-SNE dimensionality reduction, which maps the 50-d vector to the 3D VR space. For each image we display the projected 3D VR position, the ground truth and the prediction scores (top-5 scores). Our VR environment is created with Unity3D and uses the Oculus Rift CV1 with Oculus Touch controllers for interaction. Each input image is displayed based on its corresponding 3D vector and color coded by label. The user can move around in the VR space and change image positions by using hand gestures.
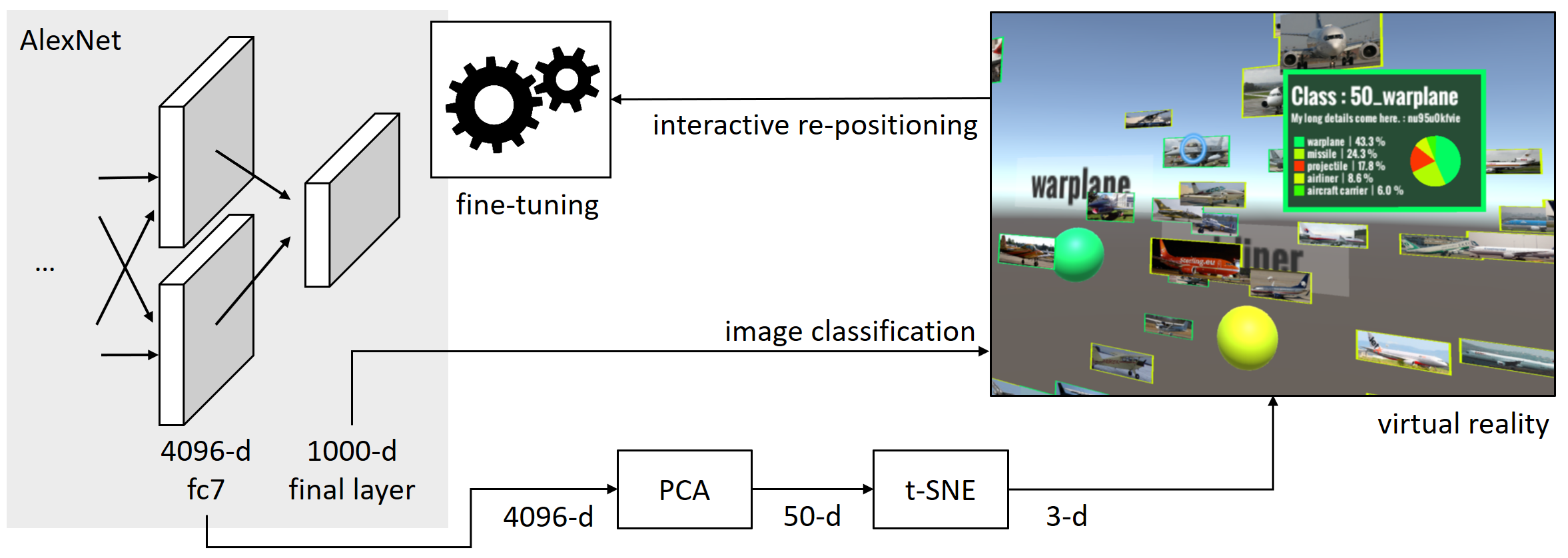
After the user moves an image, the new location can be used as parameter to fine-tune the model. We distinguish two cases: (1) the image was re-labeled because it was moved from one cluster to another, or (2) the image was moved inside a cluster without changing the label. In the first case we assume that the instance now belongs to a different class and re-train the model with this information as input. For the second case we approximate the repositioning step through re-training the network with the same image and label, as it was not moved between clusters. Depending on the distance of the new position to the cluster centroid we apply heuristics to declare how many times the image is used in the re-training step. In either case, after re-training is done, all images are again processed by the network and move to their updated position. Due to the nature of the fine-tuning process, it is not guanteed that the image moved by the user will stay at its designated position, but we allow smooth animations in the 3D layout change. The entire fine-tuning process can be repeated iteratively.